Continued from TypeSystemCategoriesInImperativeLanguagesTwo
Are you sure the problem is in understanding TypeSystem categories defined by your model [tag model], as opposed to simply developing a better understanding of the language-specific peculiarities of (I presume) PHP, ColdFusion and JavaScript? In other words, does your model do a better job of explaining PHP peculiarities than the PHP manual?
Yes!
Can you give an example of where your tag model explains something that the PHP manual does not?
For example, here's the PHP online manual's description of is_numeric:
is_numeric — Finds whether a variable is a number or a numeric string
It does not explain what a "numeric string" is, which is a seemingly contradicting term. Ideally they'd hyperlink that phrase to a decent explanation and a way to empirically test for it's existence.
A "numeric string" is a common term for string containing a sequence of characters that conforms to the language's definition of "numeric". It's tested by using is_numeric(). is_numeric returns true if its argument is of numeric type, and true if it's a string containing a sequence of characters that conforms to the language's definition of "numeric". How does your model better explain it?
That is incorrect. "is_numeric" can return True even if it's not a string. Notice the "or" in the definition/description. It implies there are two "kinds" of variables that can return True for this function.
I think you must have misread what I wrote. I did write that "is_numeric returns true if its argument is of numeric type ...", i.e., when it's not a string type but is a numeric type.
And where is the definition of "numeric" in the manual? It should be a hyperlink(s) on the term(s) if they wanted to "do it right". Thus, I already have evidence that the manual is crappy.
The online PHP manual is notoriously crappy. For example, in various places it describes function arguments as being "variables", even though they are values that can be the results of expressions. However, "numeric" is universally understood. You are correct that a good and comprehensive manual should define it, but isn't this simply an argument for a better PHP manual rather than a justification for an abstract model?
No, "numeric" is NOT universally understood, at least not in a concise way. "gettype()" can return "String" for an otherwise "number-looking" variable (output). Again, this gets back to colloquial notion-y concepts of "types" versus something more clearly modeled, i.e. "explained".
"Numeric" is certainly universally understood as "represents a number". What this means in terms of a given language is dependent on the language definition, though I doubt any languages would not recognise integers as numeric. This has nothing to do with "colloquial notion-y concepts of 'types'" and everything to do with individual language characteristics. Entirely independent of whether 547894597854 is a valid integer in one language and invalid (perhaps because it's too long) in another, or whether 10E12 is a valid double or not, or whether 0x67 is recognised as an integer or not, and so on, is the consistent notion of "type" -- a set of values and associated operations.
What gettype() returns is dependent on how gettype() is defined. It has nothing to do with what "type" means. In this case, it appears gettype() returns name of the type of its operand, even if it's a string that contains a sequence of nothing but numeric characters.
Yes, it "appears", based on samples etc.
I based "it appears" on your description, and the description in the PHP manual.
So you agree that "'numeric' is NOT universally understood, at least not in a concise way."?
"Numeric" is universally understood, and concisely, as "being a number". However, that is obviously not a rigorous definition; the rigorous definition of "numeric" varies somewhat from language to language.
And potentially per operator. Thanks for proving my point.
And what is your point?
It's not "universally understood in a concise manner". If it varies per language, then that strongly implies that there is no "universal".
The details vary from language to language, but the essential characteristic is universal: "It's a number", which is very concise, too. Details about whether "it's a number" includes or excludes exponential notation, the maximum number of digits to the left/right of the decimal point, whether NAN is recognised as a valid value or not, etc., all depend on the specific numeric types within a specific language but the overall concept is universally understood.
Note that "numeric", as used in is_numeric(), is clearly defined in the PHP manual. See http://php.net/manual/en/function.is-numeric.php in the "Description" section, to wit: "Finds whether the given variable is numeric. Numeric strings consist of optional sign, any number of digits, optional decimal part and optional exponential part. Thus +0123.45e6 is a valid numeric value. Hexadecimal (e.g. 0xf4c3b00c), Binary (e.g. 0b10100111001), Octal (e.g. 0777) notation is allowed too but only without sign, decimal and exponential part." That seems both clear and concise, though the "finds whether the given variable is numeric" should probably be "finds whether the given expression is numeric". Unless "variable" is meant to refer to the function parameter?
What is the "essential characteristic" exactly? You need to be careful when you toss out terms like that.
The essential characteristic is that "it's a number".
And getType() could tell us it's a String even if is_number() "says" it's a number. Is one of them lying, or is it relative? Which one is ignoring this magical "essential" thing?
PHP is a Category D1 language (see TypeSystemCategoriesInImperativeLanguages) which means types are associated with values, so getType() is returns the name of the type associated with the value of its operand. For is_numeric(), if the type associated with the value of the operand is numeric (i.e., float or integer), it returns true. The is_numeric() operator knows that a string may encode a numeric value as a sequence of characters, so if its operand value is associated with the "string" type, it parses the string to see if it encodes a numeric value as a string of characters and returns 'true' if it does. Otherwise, if none of the above are true, it returns false.
But a D1 language could ignore the parsing step, such as what is_bool() does (looks at tag only). I and some language commentators believe that to be a mistake, but it is a language design option for a given operator nevertheless. They could have very well done the same with is_number(). The colloquial notions don't address these kinds of issues specifically and won't tell us exactly how is_x functions act in Php or any other dynamic language. QED. Give it up, you lost the colloquial argument yet again. Enough already, pull the plug on your bloated ego and accept defeat, for I'm tired of re-winning the colloquial argument over and over. My shelf can no longer hold all the trophies.
Sure, a D1 language can "ignore the parsing step" and why not? The author of a function can make a function do whatever he or she likes, especially in dynamically typed languages where function parameters are rarely statically typed. Whether some functions are a good or bad idea is a different issue entirely.
I'm not sure what you're congratulating yourself for, or what "colloquial argument" you think you've won.
- "Type" is a vague word and existing writing on them sucks rotting eggs.
- You're congratulating yourself for "type" being a vague word? That doesn't really make sense.
- How the fudge did you interpret it that way? Nevermind, I don't want an answer anytime soon.
- {He said he wasn't sure what you were congratulating yourself for. In English, when one responds to such a statement, it's supposed to be about what you were responding to, unless otherwise indicated. In this case, that would be what you were congratulating yourself for. Your response was "'Type' is a vague word." It therefore follows that you were congratulating yourself because "Type" is a vague word.}
- He stated that it depends on the language author, which means it's not universal but controlled by the author's whims.
- {What a function that's part of the language does is entirely dependent on language author. The author could have is_numeric() return true if the camera attached to the computer is recording someone doing the watusi and false otherwise. That wouldn't change the fact that the meaning of numeric is universal. (It also doesn't change the fact that how numerics are represented is also dependent on the whim of the language definer.)}
- Back to the Country Music analogy: yes "country music" could be said to be recognized "universally", but in a rough "notion-y" kind of sense with plenty of gray areas. It's too imprecise for distinguishing and predicting the more subtle issues of "types". We want something more rigorous and objective, NOT just a fuzzy notion. This seems pretty obvious to me, but for some reason is not sinking in with you two. (And usable by rank-and-file developers, not just Phd's.)
- "Numeric" is universally understood to mean "it's a number". As evidence, look in any dictionary. However, a concept being understood by humans is quite different from a concept being parsed by a computer. The former is "notion-y" -- depending on what you mean by "notion-y" -- but it becomes precise, rigorous and objective when it's implemented in a parser, expressed via regular expressions or an EBNF grammar, and/or any of a variety of other mechanisms for implementing language recognisers. Although "numeric" is universally understood by humans, how "numeric" is recognised by a machine is entirely up to the whim of the language designer. Various conventions for this have emerged over time -- to the point of becoming de facto standards for representing float, int, long and so forth -- but EsotericProgrammingLanguages sometimes deviate from this for humorous or illustrative effect. Whilst convention states that "numeric" values are usually represented using digits, +/- signs, decimal points and the like, there's nothing that says we can't have a perfectly valid language that represents digits using the surnames of the 1980 GB women's Olympic swim team and the minus sign using that little Unicode skull. It would still be universally understood to be "numeric" -- once the notation has been explained -- though it might be somewhat difficult to read at first (but probably not much worse than Roman numerals.)
- You are wandering away from the original point. "Numeric string" is an ambiguous term. It does not tell the reader anything precise or clear-cut. It's an oxymoron even, like "jumbo shrimp" or "military intelligence" or "original copy". How does a "numeric string" differ from a "stringy number" or "numeric number" or "non-numeric string" in a clear, verifiable, and precise way? The Php manual does not (directly) explain all of this; it's just a ball of hand-wavy vague type fuzz.
- The PHP manual explains it clearly at http://php.net/manual/en/function.is-numeric.php in the "Description" section, to wit: "... Numeric strings consist of optional sign, any number of digits, optional decimal part and optional exponential part. Thus +0123.45e6 is a valid numeric value. Hexadecimal (e.g. 0xf4c3b00c), Binary (e.g. 0b10100111001), Octal (e.g. 0777) notation is allowed too but only without sign, decimal and exponential part."
- It does not explain the difference between "numeric" and "numeric string".
- A "numeric string" always means a sequence of ASCII, Unicode, EBCDIC or whatever characters that encode a number in a value of string type. "Numeric" means "a number". "Numeric type" means a value of numeric type. These phrases have been in general use since as long as I've been programming, which is over 35 years. I can only assume they were in use well before that.
- In dynamic languages, "numeric numbers" can potentially satisfy those criteria also. Remember, some can automatically "convert" as needed. And you didn't answer the question: how does one tell (test) the difference between a numeric string and a numeric number (or whatever the first one is in the above manual statement).
- True, in most cases numeric values can satisfy all the criteria of being "a number", such that we don't care whether a value is a numeric string or of a numeric type. In a well-designed language, it should be invisible. In some languages (*cough* PHP *cough*) it's exposed, for better or worse, but there's usually a function like gettype() that returns the value's type name, which you can use to distinguish numeric values from numeric strings.
- Then the manual should say that. It doesn't. One has to guess and test. QED.
- The manual does say that. See http://www.php.net/manual/en/language.types.intro.php First line: "PHP supports eight primitive types" and a little later on the same page, "To get a human-readable representation of a type for debugging, use the gettype() function."
- It does not define "numeric string" and "numeric" in terms of that. It does not tell us whether "numeric string" is a "primitive type", two types, a non-primitive type, etc.
- It doesn't have to. (Though the description for is_numeric() does make it clear there's a difference between numeric values and numeric strings.) It's self-evident, and uses familiar terminology. The manual doesn't have to warn you that misuse of a loop can result in an infinite loop either, nor does it have to elucidate all manner of other well-known programming terminology.
- Just because you claim it's "self-evident" does not make it so. (And yes, it does suggest there is a difference between "numeric" and "numeric string", but does not explain it and does not link to the explanation even if by chance it's buried somewhere else.)
- That's true. There are inevitably people for whom common and commonly-understood terminology is not recognised, and ideally every manual would come with a glossary of every technical term it uses. Some do. The PHP manual is apparently targeted at programmers with a reasonable degree of programming experience, and perhaps technical writing resources are limited, so there are terms it sees fit not to define.
- It is NOT "commonly understood" in a clear way, only as fuzzy impressions.
- How do you know?
- Because I did an OfficialCertifiedDoubleBlindPeerReviewedPublishedStudy, just like YOU did, my friend.
- The fact that millions of programmers successfully create programs on a daily basis would suggest that "numeric" and "numeric string" are commonly understood.
- I already explained how and why it happens and will not re-create that material here.
- Your arguments are not compelling.
- Neither is the counter argument because it's only anecdotal evidence and personal speculation about how brains work.
- If that is so, then perhaps it is inappropriate to claim that frequently-used terms are "NOT 'commonly understood' in a clear way, only as fuzzy impressions", because your claim is only anecdotal evidence and personal speculation. Perhaps the only thing you should reasonably and accurately state is that certain frequently-used terms are "only ... fuzzy impressions" to you.
- It works both ways.
- But there's clear evidence that frequently-used terms are commonly understood: the simple fact that if they weren't commonly understood, they would vanish under a hailstorm of profitably helpful explanations. This is particularly true in the computing field. Why don't I see bookshelves stacked with "TypeSystems for Dummies" books?
- Largely because they vary too much per language, and partly because the industry hasn't found a good way to describe types in clear ways. And like I keep saying over and over repeatedly, most programmers use a combination of fixing spot issues as they come up and/or using defensive programming with lots of explicit conversions to "be sure". I've successfully written a good many programs myself without knowing much about how the particular language handles type issues, and type bugs were relatively rare.
- The industry clearly describes types in many language references. The PHP manual is hardly an example of good practice or even typical practice.
- You are the last person on Earth I'd use as a reference specimen to measure "clearly".
- Excellent -- please don't rely on me. Rely on your own reading. Look for more language references than just the PHP and ColdFusion manuals.
- {Even those other oxymorons have meaning, and some of them aren't ambiguous. The usual meanings for your four statements would be that "numeric string" differs from "stringy number" since the former is defined and the latter isn't. "Numeric number" would just be another name for "number" and would differ from "numeric string" in that it would not be a string. A "non-numeric string" would be any string that isn't a numeric one. I'm not sure why you think the PHP manual should have to explain this. It's just standard English after all. The PHP manual would assume that you know this stuff already.}
- If you think all that is clear, then we live in a fucking different universe! Holy damn! To me is either gobbledygook, or a Lewis Carole puzzle (or both).
- {Then learn some English. There's nothing non-standard there.}
- Fuck off, troll!
- You're not being trolled. "Numeric string" is a recognised, familiar concept in programming. It's a string containing a sequence of characters that represents a numeric value.
- You've offered no metric for familiarity nor clarity, you just claim out of your ass. By that standard, "0" is a "Numeric Boolean String" in CF because it can be processed as all 3 in at least some circumstances.
- No need. There's no "metric for familiarity nor clarity" for the terms "loop" or "statement" either, yet these terms are universally recognised among programmers.
- Yes, but there are also grey areas. They are "notion-y", not precisely defined.
- They don't have to be defined in order to discuss them in general. Every programming language precisely defines them, however.
- Of course, they are "good enough" the majority of the time, I don't dispute that. And yes, each programming language has its own interpretation, but it's often not easy to figure out what that interpretation is.
- The problem, then, is not a lack of models but a lack of good documentation for particular languages.
- I haven't seen it done well with English alone. If and when I've seen it done well, then I'll abandon attempts to present a model instead. The saying "a picture is worth a thousand words" is often true. An explicit familiar data structure with clear state and clear parts and clear relationship between the parts (per data structure conventions) often is far more powerful than English alone. Words are often very poor at that without lots of verbosity because they have to re-invent in text what the data structure does out of the box. Perhaps "verbal thinkers" think otherwise, but I ain't one of them.
- Perhaps you could present diagrams or illustrations that visually clarify how popular programming languages actually work? That would be useful, and far, far less likely to draw resistance than what's been presented so far.
- That may be overkill; too many details. The tag model [fixed typo] is simpler because it eliminates elements not essential to type issue emulation. It only draws resistance from those who appear to be vested in the status-quo (expensive education and consulting).
- What details do you consider to be overkill?
- Do you really think your "flag model" (Wasn't it your "tag model" yesterday?) is being resisted because of a status-quo investment in "expensive education and consulting"? Or, do you think it might be because we object to arbitrary use of unfamiliar but overloaded terms ("tag") with neither definition nor explicit mapping to familiar terms; the lack of a definitive description -- such as TopsTagModel -- to precisely describe the parts of the model with rules for putting them together; apparent unnecessary deviation from how popular imperative programming language TypeSystems actually work; arbitrary avoidance of an entire language category (statically-typed languages); and failure to explain common language behaviour like why print("34" + 34) prints "3434" in some languages, 68 in others, and is an error in a third category?
- The others I already explained and will not re-recreate those arguments here. You have not done a reliable popularity survey either: you are biased and will cherry pick your popularity evidence. The last one if flat wrong and is an appalling display of slackage of attention. ThirtyFourThirtyFour illustrates the tag model explaining both results (3434 and 68. I did forget an "error" example, and have since added #8). Did you completely forget that I created that topic to give examples after you've been pissing around in that very topic for weeks??? WTF-city. And it's a hell of a lot more detail than you've given under your vague model. (Note there are many paths to both results, and I don't think I covered every path, but rather gave representative example paths. Normally more (different) experiments would be needed to narrow down the modeling paths.) And you haven't explained clearly why it allegedly differs from actual implementations other than they do certain things for efficiency purposes, which I'm ignoring to get a simpler model.
- Is ThirtyFourThirtyFour meant to be part of the description of your model? It looks like an ad-hoc description of language behaviour observations at the top, followed by a ThreadMess, followed by the start of my explanation of how operator invocation actually works in most popular imperative programming languages, followed by more ThreadMess, and finally ending with the rest of my explanation of how operator invocation actually works in most popular imperative programming languages. I didn't realise ThirtyFourThirtyFour was (some? all?) of your model. Given that it (apparently) is, could you point out where it elucidates the components of your model and describes the rules for how they are put together?
- I didn't claim that topic was the complete description, it is an application of the model to specific situations. That should be obvious, but for some odd reason in your alien head it's not. Go back to Orion, I'm tired of trying to communicate with non-humans with weird thinking processes
- Given that it's you who is so often at odds with an educated majority, I submit that it might not be us who have the weird thinking processes.
- "Weird" is relative. I'm trying to help plebeians, not elites. I don't give a shit if I don't please the elites. Did you say "majority" there?
- You appear to be evading a direct response to what is an obvious conclusion.
- You have no reliable surveys quantity-wise. Stop pretending. Why do you keep bringing up popularity and/or commonness of knowledge with so little solid info to back your speculations? Something psychological is making you focus on such. I suggest a deeper self assessment. If you disagree with my anecdotal assessment based on your own anecdotal assessment, then just leave it at that. Why keep bring it up?
- I bring it up because it's an obvious conclusion: That you're a lone voice in the wilderness, proclaiming your own limitations loudly as if to convince us they belong to everyone.
- If you wish to believe that, go ahead. I'm tired of arguing about that. My summary assessment is that your evidence is very weak.
I do agree that linguistic conventions
could be setup such that language alone could perhaps be "good enough" for such issues and we wouldn't need XML models etc. However, that's not the current state of affairs. If you want to pursue that, fine, but until it's been presented and vetted, the tag model is superior because it relies far less on English.
That's impossible to judge, because although how popular imperative programming language TypeSystems work is described at the top of TypeSystemCategoriesInImperativeLanguages, there is no equivalent exposition of TopsTagModel. How can we compare in the absence of that?
Why would I want to copy your vague, poorly-written description or use it as a model?
Have I suggested that you should? It seems somewhat disingenuous to claim that your "tag model is superior because it relies far less on English" without a clear exposition of TopsTagModel so that we can test it to see if it's "superior because it relies far less on English". Since it appears to be spread over many pages, it's hard to tell whether it "relies far less on English" or not, especially as it appears you've expended a lot of English in an attempt to explain it.
Perhaps both approaches are sucking (or are WetWare mismatches). I didn't intend to write so much about it, but for reasons that escape me it's not sinking in with you. I at least attempt to model the processes of concern via reading and writing of a reference data structure (XML). One can see the data structure being analyzed via pointers showing what the model interpreter is "looking at" during a given step and/or changing the structure in a similar fashion. I don't know how to be any more explicit than that without writing a per-language or per-op interpreter that uses the reference structure. Would doing such be helpful?
That's what my WetWare likes to see: a reference representative data structure using familiar industry data structure idioms, such as XML or SQL, and step-by-step rules for how and when these change. The "home" of state information and the relationship to other state information is clearer that way because it's using known industry-standard sub-parts. Your use of English as a substitute confounds the hell out of me and appears inconsistent with other writers of typeness.
{Why it's not sinking in with us is quite clear. It's not sinking in because you won't tell us the important parts. E.g. the rules for setting up your model from a given language. Without those, we can't know how to map the language parts to your model's parts. You appear to have some rules since you've indicated indirectly that certain mappings aren't correct, but I have no idea what those might be. (Especially since those mappings still preserved the relationship between source, input, and output.)}
I cannot offer concrete rules, only suggested patterns of exploration such as "here are some things to try", because every language is different. If a newly-encountered language fits common and known patterns, then the suggestions will be of immediate help. No model can anticipate all possible languages. Sherlocking around will sometimes be necessary. This is back to the Trek planet analysis analogy. Thus, are you asking for concrete rules, or are suggested tests okay with you? If the second, most of them have already been given or are obvious extensions (such as testing more than just numbers and strings if a lang offers them). I agree they could be cleaned up and organized better, but you've already seen most of it multiple times but didn't seem moved by such the first, second, third, etc. time such that I doubt repetition number 4+ will be the magic repetition number.
A model has clearly-defined and identified parts and precisely articulated rules for how they are put together and how they relate to the real world being modelled. If you "cannot offer concrete rules, only suggested patterns of exploration", then what you have is a guide for exploring some aspects of a language. That's fine, and perhaps useful for studying language behaviour, but it's not a model.
- Because nobody can reliably predict the future, nobody. Not me, not you, not your dog. Your model suffers the same limitation of mortal life, so stop your bitchin'. Perhaps I should call it a "model-building toolkit" which assists one in building language-specific models for type-related behaviors. Would you be satisfied with that?
- {And that's relevant how?}
- A perfect model would require predicting the future, and since that's not feasible to mortals, no mortal can make a perfect model. Thus, you set up an impossible goal and then fault me for not satisfying that goal (even though your model doesn't either).
- {While predicting the future is a common use of a model, it's not the only one. So why are you requiring it?}
- I mean predicting a future language. Nobody can create precise rules to model all possible future (unseen) dynamic languages.
- No one's asking you to predict future languages. You wrote, "I cannot offer concrete rules, only suggested patterns of exploration ..." That means it's not a model, whether it predicts the future or not.
- What definition of "model" are you using? Nevermind, forget it, don't want a LaynesLaw loop. Call it a "Tiffyonk". The purpose of the tiffyonk is to facilitate building models of type-like dynamic language behavior as the languages are encountered. It's not guaranteed to work for all possible dynamic languages. My tiffyonk is better than your tiffyonk.
- Until you've demonstrated how your tiffyonk facilitates building models by building a model, we'll have to assume that isn't true.
- I did, but your head is broken and I cannot find the debugger for it.
- What does that mean, exactly?
- Take a best guess.
Re: "(Especially since those mappings still preserved the relationship between source, input, and output.)" -- Please elaborate.
{It means that given the same code and input, I was able to produce an alternative mapping to the parts of your model that didn't break any of your stated rules and produced the same output as your model. (It did however result in the opposite conclusion.)}
I don't know what you are talking about.
{It's where you complained about shoving the quotes up the value on TypeSystemCategoriesInImperativeLanguagesTwo.}
Again, I was talking about parsing in an informal way there. Also, quotes are not part of the value: you put non-value parts in the value, making "value" lie. Stated another way, in the tag model you don't put declaration quotes (delimiters) in the value. If you want to make an alternative model where you do, be my guest.
{Like I said. You appear to have some rules for how to map the language to your model. Otherwise, how would you tell if the value is "lying"? And how would you handle the language described there where the quotes show up in the output if you concatenate in a different manner, if you don't put the declaration quotes in the value?}
Please illustrate with some pseudo-code.
{You haven't answered the questions yet. How can I illustrate it?}
I meant "concatenate in a different manner".
{Ok. Using the language where you complained about shoving the quotes up the value on TypeSystemCategoriesInImperativeLanguagesTwo. The following code produces the string "123""123" as output.}
a = "123"
alert(concatenate(a, a))
I have no idea why a language would do that. I don't claim the tag model (kit?) can model every language, but would need more info about this odd language of yours to suggest modelling approaches, including whether the tag model is a poor fit.
What's notable here is that the description at the top of TypeSystemCategoriesInImperativeLanguages has no difficulty modelling it.
In a language that only executes in your head. It's scramble-talk to me. That aside, you still haven't explained WHY one would want a language that behaves in such a way, regardless of how "types" are modeled.
It doesn't matter why. What matters is that the conventional model works to describe it, and yours does not.
Reversification. I went step-by-step through examples and showed how and when the data structures changed. You didn't.
In the conventional model, there is one and only one data structure change: Assignment to a variable replaces the variable's value with another value. That's it.
What about "a=3;print(a);a='3';print(a);" in tagged languages (like Php)? We don't even need to know or care if "the value" has changed under the hood. It's not necessary to model such a change such that one may choose to skip that in a model without consequences.
Yet, precisely what is happening is that the value in variable 'a' has been replaced with 3, and later replaced with '3'. What understanding about PHP is gained by trying to "skip that"?
Prove it.
(a) Do you really think PHP assigns a new value to 'a' in "$a=3;print($a);$a='4';print($a)" but not "$a=3;print($a);$a='3';print($a)"?
- That's an implementation detail. The result would be the same either way. The interpreter may check the existing "value", see it's the same, and thus not change it, only changing the tag (or whatever "affects" getType().) If RAM writes are far more expensive than reads for a given machine, an interpreter designer may choose such a route.
- True, that's conceivable, but that's not what PHP does. It does what the PHP manual says it does: "... the entire value ... is copied into the destination variable."
- If Php was rewritten for a given platform to work the other way, would you suggest forking the manual for the new platform? I'm asking to try to tease out what you view as the purpose of the manual.
- Fork the manual, no, but I'd certainly expect the un-forked manual to mention that such optimisations occur on certain platforms, if only as a footnote. However, dynamically-typed languages do not generally associate types with variables. That's why another name for dynamically typed language is "value typed". I wouldn't expect a few specialised, relatively rare, internal optimisations to affect how language categories are modelled in general, so it seems appropriate to model dynamically-typed languages as having values that have types (necessary to account for expressions) but variables do not have types (which is why you can assign them any value of any type at any time.)
- Compression and caching are common technologies that may complicate the implementation in similar ways but are not worth mentioning in the "language description" other than sections on performance issues. In this case, I don't even think a footnote is warranted because it may likely confuse readers. The language description is often a UsefulLie. Yes, it may be "babying" the readers, but that's life in documentation-land.
- Fair enough. Such things are probably worth divvying up into a "technical guide" for those who care about the innards, and a "user's guide" for those who don't.
- So you are agreeing that a somewhat idealized or "fake" model of the language is being presented to the language user such that it may not fully describe actual implementation, at least as the first representation given.
- I disagree with presenting a "fake" model of the language, where "fake" means it does not reflect what the language actually does. I have no problem with presenting an accurate abstraction or simplification (e.g., that leaves out details of caching or other optimisations), but not to the point of being inaccurate or incorrect. The latter begs unintended consequences; it's risky to "lie" about what a language does.
- I agree it should describe how input (data and source) translates to output accurately (AKA, "model I/O correctly"), but I'm not sure if that correspond to your usage of "do" or "does". I advise you to find a better replacement for those.
- Note that most programs involve a lot of code between getting the input at the top and producing output at the bottom. Apparently, that code does something.
- Yes, it transforms input into output.
- Exactly. And to accomplish that, code -- statements, expressions, assignments -- are used to describe algorithms of arbitrary complexity. Surely they must do something, no?
- But there are different ways to model/emulate those statements etc. in terms of their I/O (which may be tested individually).
- The key ingredients of an algorithm in imperative programming languages -- at least those ingredients that are particularly related to TypeSystems -- are variable assignments and expressions. Neither of these are I/O, unless you're relying on a highly nuanced and unusual definition of "I/O".
- We use I/O to make inferences about them. Often we use simplified experiments to isolate the elements/features we wish to study. I/O is our "port" to interact with the black-box we call the interpreter. If we test a new interpreter for a given language to make sure it runs our old programs from prior versions or other venders, we compare I/O, not implementation. The I/O is our reference point, not the implementation. (Reminder: "input" includes the source code, not just the data.)
- We use I/O (or a debugger) to experiment with statements, certainly, even though we risk conflating I/O behaviour with the behaviour of the statements. But how do you explain the many language statements that appear in the average algorithm in terms of I/O, when the majority of them -- if not all of them -- are not I/O?
- I've already explained the problems of using debuggers as a standard reference point and won't repeat them here other than remind you about vendor swappability. Using I/O as the standard reference point is NOT the ideal, but it's the best we have because internal implementation does not define the language from a developer's perspective and can change. We are pretty much forced to use I/O to "define" a language in a similar way that we have to use "crash trace prints" to explore sub-atomic particles (in atomic accelerators). Crash prints are not the ideal, but they are the best we have. If we compare two different interpreters from two different vendors to make sure they both implemented the same "language" we use I/O and only I/O. There is nothing else we can safely rely on. Debuggers guarantee nothing. If you write your apps to depend on debugger behavior/output, then you deserve to be fired when it goes sour upon an upgrade or vendor swap. Bitch about that ugly reality all you want, but you have not offered a better alternative. Sometimes Reality Bytes. --top
- Actually, the "standard reference point" for most languages is the language reference, but for empirical testing debuggers are far preferable and considerably more reliable than using I/O -- given they don't risk conflation of I/O behaviour with statement behaviour -- especially when learning a new and unfamiliar language. Also more reliable than I/O is creating UnitTests. I don't know what the issue is with "vendor swappability"; I must have missed that part -- PageAnchor, please? However, the above doesn't answer my previous question: How do you explain the many language statements that appear in the average algorithm in terms of I/O, when the majority of them -- if not all of them -- are not I/O?
- Written descriptions are too subject to misinterpretation. If you can rework the experiments into unit tests, be my guest. We won't agree on the debugger issue it appears, so hopefully it won't be an issue here.
- When written descriptions are too subject to misinterpretation, we have diagrams. When diagrams are too subject to misinterpretation, we have notations.
- There are other documentation options as described in TypesAndAssociations.
- Such as?
(b) What does this do: "$a=$x;$a=$y;"?
(c) See http://www.php.net/manual/en/language.variables.basics.php where it is written, "... variables are always assigned by value. That is to say, when you assign an expression to a variable, the entire value of the original expression is copied into the destination variable."
We are getting off track. What I meant is that "value" is ambiguous and that there is more than just the value being changed in "a=3;print(a);a='3';print(a);", but it largely depends on how "value" is observed/tested and defined in terms of such tests. If you say getType() "looks at" the "value", then the value has changed (is "different"). However, the output of "print" is identical. How does one empirically verify if the "value" is different between the first "a" and the second "a"? Forget the word "change", and focus on "different" instead. Does getType use the "value"?
No, in "a=3;print(a);a='3';print(a)" only the variable's old value is replaced with a new value. A value consists of a representation and a type reference, and gettype() only uses the value's type reference. That's why "$p=3;gettype($p)" and "gettype(3)" and "gettype(3 + 4)" produce the same result. Furthermore, "gettype(3 + 4)" can only be explained by the existence of values with type references, which corresponds with the definition of a value being the result of an expression, and with a value being composed of a representation and a type reference.
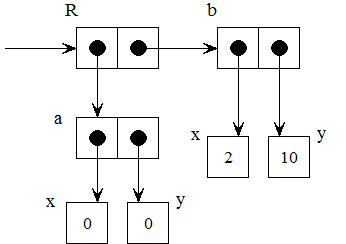
I'd like to rework your XML from TypeSystemCategoriesInImperativeLanguages a bit here for discussion. For one, I prefer the "parts" have named labels for clarity and discussion reference such that I'm making the "value's value" (for lack of a better term) be an attribute. Is this a "reasonable" representation to you?:
<!-- Example PTX02, representation of a$='3' -->
<variable name="a">
<value type_reference="string" representation="3"/>
</variable>
The differences appear to be (a) converting the representation from content to an attribute, and (b) renaming the "type" attribute to "type_reference". I'm fine with that.
So if we use this structure to model variables, is it okay to say, "Some operators only look at (use) the type_reference attribute of a given operand and some only look at the representation attribute (or at least behave that way when analyzed)"? (I can't think of any that require looking at both, but won't rule it out just yet.)
Yes, that's fine.
Okay, so when I say "tag", I'm talking about the "type_reference attribute", and when I talk about "value", I'm talking about the "representation". Let's see if that holds up.
But then you're using a PrivateLanguage. Why not simply say "type reference" (or, as we usually do, just say "type") and "representation"? Also, what do you call the association of a "value" and a "type_reference attribute"? I call it a "value".
I believe we've been over that at least 3 times. Colloquial usage of "types" is vague and overloaded. You say it's not, I say it is. I don't want to re-re-re-re-re-re-argue that yet again repeatedly multiple times redundantly. Both side's arguments are based on anecdotal info about common/popular perceptions/beliefs and we are an at anecdotal impasse. Let is sleep.
Repeatedly, I have responded to your allegation that "colloquial usage of 'types' is vague and overloaded" with the same question: What problem does the alleged "vague and overloaded" use of the term "type" cause that use of the term "tag" solves? I haven't received a clear answer.
The "multiple simultaneous types" issue with isX() kind of functions, their difference/contradiction with typeName()-like functions, and the never-ending CFargument debate are examples.
There is only one type associated with the representation of a value. Values of other types can be encoded in the value. This is explained at TypeSystemCategoriesInImperativeLanguages.
"Encoded" is too subject to interpretation, per TypesAndAssociations.
What does "too subject to interpretation" mean, in this case? Can you give an example of how "interpretation" could be mistaken?
See the pointer diagram on page 98?:
http://www.tutorialspoint.com/pascal/pascal_tutorial.pdf?page=98
And more complex variations:
http://www.billthelizard.com/2010/10/sicp-23-rectangles-in-plane.html
Those kind of diagrams were very helpful at illustrating and modeling pointers in my opinion. "Types" needs something similar, and the best representation will probably split "type tag" off from "value", such as a two-chambered box.
Diagrams and notations are certainly helpful. Here are some two-chambered (where appropriate) ASCII boxes:
- In statically-typed languages -- Category S -- variables are [ Value | Type ] and values are [ Representation | Type ].
- In some dynamically-typed languages -- Category D1 -- variables are [ Value ] and values are [ Representation | Type ].
- In other dynamically-typed languages -- Category D2 -- variables are [ Value ] and values are [ String ].
How's that?
That's a start, but I wouldn't call it "type" because "type" is overloaded as explained a jillion times already but you keep never getting such that we repeat the same argument over and over repeatedly multiple times redundantly. And why do you use the term "representation"?
Except that where I use "type", it is a "type" reference in every popular imperative programming language. "Type" will always be int or char or float or double or string or bool or some other type. Why does it matter if the term is overloaded? (Not that I'm saying it is overloaded, but let's assume it is.) How do you expect a model to be useful if it doesn't have recognisable parts?
- That's not a mandatory requirement for a useful model. All else being equal, we'd use common terms and notions, but it's not equal because "type" is vague and overloaded in colloquial-land. (Yes, I know you disagree.)
- Again, why does it matter if the term is vague and overloaded? Surely it's no more vague and overloaded than "tag", which is undefined in this context and quite obviously overloaded?
- Tag's potential overlaps are in different enough areas/domains as to not cause significant problems. Anyhow, let's settle on the utility of the model first and after concern ourselves with the best possible name. For now I'll use "tag" as a working name.
- What "significant problems" does the (supposedly) vague and overloaded term "type" cause that are solved by "tag"?
- We've been over this territory already somewhere. I'll see if I can find the link.
- That would be helpful.
- It was related to the cfArgument example and your usage of "type" when describing that, even though it involves no tags in my model.
- So? That sounds like a problem with your model -- cfArgument is unquestionably related to types; it's used to restrict function invocation arguments to specified types via a "type" attribute. How does using the term "tag"... I don't know... Fix this?
- There's more to the model than just tags. Lack of a tag or non-usage (no reading of) the tag conveys useful information also. As a rough analogy, we call it the "light switch", not the "non-light-switch" even though it's used to turn off the light.
I use the term representation because every value has a representation. In the vast majority of computer systems, it's inevitably a string of bits, but we can also consider it a string of bytes, words, characters, or whatever we like. The type reference tells the language internals how to interpret the representation, so that (for example) a bit string of 110110 with a type reference to 'integer' means it's an integer value 54, but the same bit string with a type reference to 'character' means it's the ASCII character '6'. A value is the association of a representation with a type. In other words, every value has a type reference, which we usually shorten to simply "every value has a type". In languages where all values have the same type -- usually a string of characters aka a character array -- the type reference may be implicit, as shown above in Category D2.
Re: "every value has a type" - Every value can have multiple "types" at the same time by some accounts. In fact, I'd say it's better to say it's up to each operator rather than try to tie it all to some universal central concept. Yes, there are common/typical conventions, but that's not good enough for rigid global declarations about "types".
Every value is associated with one and only one type in popular imperative programming languages, except in those languages that support multiple inheritance. However, it is frequently possible to encode a value of one type in another. For example, the string "true" can encode a boolean value, and the string "123.45" can encode a numeric value, and the number 1448 can encode an even number, and the number 13 can encode a prime number. This fact is fundamental to programming language operation, because a value of type string -- which happens to encode the source code for a program -- is parsed (according to the rules of a grammar) to identify the values of various types, expressions, statements, identifiers and so forth.
Sounds great, let's model it in a clear way now such that words like "encoding" are specific actions and visible state changes instead of just words.
The only state change is in assignment, where a new value replaces a variable's old value. An operator can be written to recognise any possible encoding in its operand(s). Both of these statements are true in all popular imperative programming languages.
Depends on how "value" is defined, per above.
The standard definition of "value" is that it is the result of evaluating an expression.
I mean in terms of something observable.
Sorry, not following you.
Note that I have been cavalier about including the dollar sign in some of my code snippet samples. -t
- {Notice we haven't been caviler about it.}
Sometimes, I wish the PHP interpreter were equally cavalier. What earthly reason did they have for requiring a bloody sigil?
{Really? You'd rather PHP showed a lack of proper concern?}
No, I'd rather PHP didn't use sigils. I should have written "cavalier" instead of cavalier.
I prefer Cuban cigils.
EyesRoll
SeptemberThirteen
 Php Type System Discussion
Php Type System Discussion